When it comes to date-effectivity, the tricky part is date-effective updates to the rows. It's not as simple as updating non date-effective rows. You need to know the basics of date-effectivity like what is an effective date and how it impacts search, create and update operations on date-effective records. Here, we're going to discuss different date-effective update modes available in ADF 11g and their behavior.
All the date-effective update modes are defined as constants in oracle.job.Row class as any kind of effective dated operation is performed on a row itself. Before going into details, let us take an example to explain the concepts. For example, we'll take the same example of 'Job' date-effective object and explain different date-effective update modes available. Sample application having the required code to perform the DE update operations can be downloaded from here.
The following DE update modes available in Jdeveloper 11g:
1. EFFDT_UPDATE_CHANGE_INSERT_MODE: When an effective dated row is updated in "change insert" mode, the modified row is end dated on the effective date and a new row is inserted that fits between the effective date and the start date of the next row in the effective date time line.
For example, if the Job with JobId 100000020529001 has the following effective-dated row

From the above data, you can see that the details of the job 'Apps Engineer' from 01-Jan-1990 to 31-Dec-4712. And, for example if we want to increase the salary ranges of this job to MinSal=25000 and MaxSal=35000 from 01-Jan-2011 onwards. To achieve this, we need to end date the existing row at 31-Dec-2010 and create a new record for the job from 01-Jan-2011 to 31-12-4712. For such cases, we use this EFFDT_UPDATE_CHANGE_INSERT_MODE.
 After updating the above job record with effective date 01-Jan-2011, the resultant rows will be as below:
After updating the above job record with effective date 01-Jan-2011, the resultant rows will be as below:

Again, if we want to update the MedicalCheckRequired attribute to 'Y' effective 01-Jan-1950 (till 31-Dec-2010), we need to update again with effective date 01-Jan-1950.
 After updating, the resultant rows will be:
After updating, the resultant rows will be:

2. EFFDT_UPDATE_CORRECTION: When an effective dated row is updated in "correction" mode, the effective start date and effective end date is left unchanged. We generally use this correction mode to correct the existing data of a single date-effective record (Correction mode won't create a new row, it'll just correct/modify the existing date-effective record data).
For example, let us take the same above 3 date-effective job records and if I want to correct the JobLevel of the Job record [100000020529001,01-Jan-1900,31-Dec-1949] to 1 from existing value 2, we need to correct the record in EFFDT_UPDATE_CORRECTION mode. For correction, we can use any date between EffectiveStartDate and EffectiveEndDate as the effective date.
 After correction, the result will be as follows:
After correction, the result will be as follows:

3. EFFDT_UPDATE_MODE: When an effective dated row is updated in "update" mode, the modified row is end dated on the effective date and a new row is created with the changed values.
For example, let us continue with the same above 3 rows and I want to update the JobName to 'Apps Specialist' from 'Apps Engineer' effective 01-Jan-2015, we can use EFFDT_UPDATE_MODE.
 After updating in UPDATE mode, the resultant rows will be:
After updating in UPDATE mode, the resultant rows will be:

Here, one thing that we need to keep is that EFFDT_UPDATE_MODE works only for the last date-effective row. The reason is that this mode will always create the modified new record till EOT(31-12-4712) starting from the given effective date. i.e., if we try to update the row [100000020529001,01-Jan-1900,31-Dec-1949] with effective date 01-Jan-1925 in UPDATE_MODE mode, it'll try to create the new record [100000020529001,01-Jan-1920,31-Dec-4712] which will result in overlap with the existing record [100000020529001,01-Jan-1950,31-Dec-2010] and throws exception saying 'the date effective operation will result in gaps or overlaps'.
4. EFFDT_UPDATE_OVERRIDE_MODE: When an effective dated row is updated in "override" mode, the modified row is end dated on the effective date and the start date of the next row in the effective date time line is set to effective date + 1 day.
For example, let us continue with the above 4 date-effective rows, and if we want to move the EffectiveStartDate of the Job row [100000020529001,01-Jan-2015,31-Dec-4712] to 01-Jan-2013. i.e., we want to make the 'Apps Specialist' job title applicable from 01-Jan-2013 onwards instead of 01-Jan-2015. And, you can also set/change the other attributes for the resultant updated row [100000020529001,01-Jan-2013,31-Dec-4712] (for e.g., I'm setting the JobLevel from 2 to 3).
 After updating the above rows with effective date 01-Jan-2013 in EFFDT_UPDATE_OVERRIDE_MODE will result in the following rows:
After updating the above rows with effective date 01-Jan-2013 in EFFDT_UPDATE_OVERRIDE_MODE will result in the following rows:

From the above table, you can observe that EFFDT_UPDATE_OVERRIDE_MODE didn't create any new rows. It just moved the existing ESD to the passed effective date.
5. EFFDT_UPDATE_NEW_EARLIEST_CHANGE_MODE: Updating in "new earliest change" mode is supported only in Multiple Changes Per Day (MCPD). MCPD entities are the entities that support multiple date-effective updates on a single day. We're not covering this mode in this post as it would be out of scope of this post.
Here is the method that I wrote to accomplish all of these DE update operations with different DE update modes (download the sample application for to find the method references used in the below code).
In the above method, we're actually getting the Job row effective as of the passed effective date(this will make that effective-dated row as current row) and then performing date-effective update operations basing on that row.
Instructions to run the sample application:
1. Create the required tables for illustrating date-effective operations executing the sql script downloading from here.
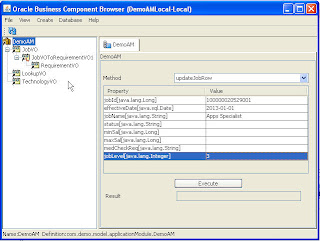
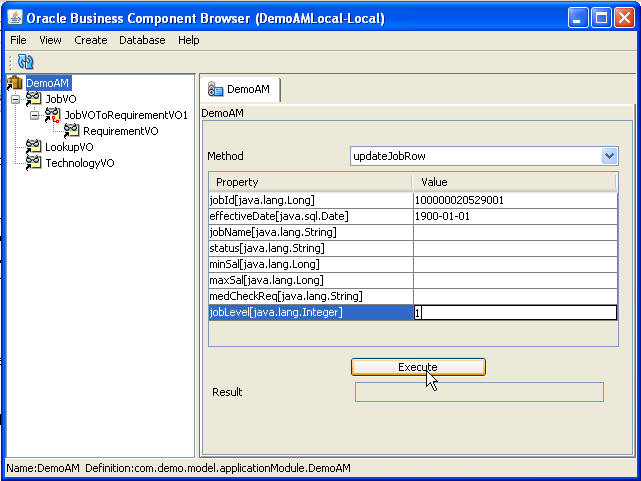
2. Unzip the sample application and, run the DemoAM. Input JobId, effective date and other attributes you want to update and click 'Execute'.
3. Change the date-effective update mode in method 'updateJobRow' each time you want to change the update mode(right now it's hard coded to EFFDT_UPDATE_CHANGE_INSERT_MODE), rebuild and continue. You can find the screen shots above how to provide input in AM Tester.
4. Query the DB to find the updated rows.
Enjoy!!!
All the date-effective update modes are defined as constants in oracle.job.Row class as any kind of effective dated operation is performed on a row itself. Before going into details, let us take an example to explain the concepts. For example, we'll take the same example of 'Job' date-effective object and explain different date-effective update modes available. Sample application having the required code to perform the DE update operations can be downloaded from here.
The following DE update modes available in Jdeveloper 11g:
1. EFFDT_UPDATE_CHANGE_INSERT_MODE: When an effective dated row is updated in "change insert" mode, the modified row is end dated on the effective date and a new row is inserted that fits between the effective date and the start date of the next row in the effective date time line.
For example, if the Job with JobId 100000020529001 has the following effective-dated row
From the above data, you can see that the details of the job 'Apps Engineer' from 01-Jan-1990 to 31-Dec-4712. And, for example if we want to increase the salary ranges of this job to MinSal=25000 and MaxSal=35000 from 01-Jan-2011 onwards. To achieve this, we need to end date the existing row at 31-Dec-2010 and create a new record for the job from 01-Jan-2011 to 31-12-4712. For such cases, we use this EFFDT_UPDATE_CHANGE_INSERT_MODE.


Again, if we want to update the MedicalCheckRequired attribute to 'Y' effective 01-Jan-1950 (till 31-Dec-2010), we need to update again with effective date 01-Jan-1950.


2. EFFDT_UPDATE_CORRECTION: When an effective dated row is updated in "correction" mode, the effective start date and effective end date is left unchanged. We generally use this correction mode to correct the existing data of a single date-effective record (Correction mode won't create a new row, it'll just correct/modify the existing date-effective record data).
For example, let us take the same above 3 date-effective job records and if I want to correct the JobLevel of the Job record [100000020529001,01-Jan-1900,31-Dec-1949] to 1 from existing value 2, we need to correct the record in EFFDT_UPDATE_CORRECTION mode. For correction, we can use any date between EffectiveStartDate and EffectiveEndDate as the effective date.

3. EFFDT_UPDATE_MODE: When an effective dated row is updated in "update" mode, the modified row is end dated on the effective date and a new row is created with the changed values.
For example, let us continue with the same above 3 rows and I want to update the JobName to 'Apps Specialist' from 'Apps Engineer' effective 01-Jan-2015, we can use EFFDT_UPDATE_MODE.


Here, one thing that we need to keep is that EFFDT_UPDATE_MODE works only for the last date-effective row. The reason is that this mode will always create the modified new record till EOT(31-12-4712) starting from the given effective date. i.e., if we try to update the row [100000020529001,01-Jan-1900,31-Dec-1949] with effective date 01-Jan-1925 in UPDATE_MODE mode, it'll try to create the new record [100000020529001,01-Jan-1920,31-Dec-4712] which will result in overlap with the existing record [100000020529001,01-Jan-1950,31-Dec-2010] and throws exception saying 'the date effective operation will result in gaps or overlaps'.
4. EFFDT_UPDATE_OVERRIDE_MODE: When an effective dated row is updated in "override" mode, the modified row is end dated on the effective date and the start date of the next row in the effective date time line is set to effective date + 1 day.
For example, let us continue with the above 4 date-effective rows, and if we want to move the EffectiveStartDate of the Job row [100000020529001,01-Jan-2015,31-Dec-4712] to 01-Jan-2013. i.e., we want to make the 'Apps Specialist' job title applicable from 01-Jan-2013 onwards instead of 01-Jan-2015. And, you can also set/change the other attributes for the resultant updated row [100000020529001,01-Jan-2013,31-Dec-4712] (for e.g., I'm setting the JobLevel from 2 to 3).


From the above table, you can observe that EFFDT_UPDATE_OVERRIDE_MODE didn't create any new rows. It just moved the existing ESD to the passed effective date.
5. EFFDT_UPDATE_NEW_EARLIEST_CHANGE_MODE: Updating in "new earliest change" mode is supported only in Multiple Changes Per Day (MCPD). MCPD entities are the entities that support multiple date-effective updates on a single day. We're not covering this mode in this post as it would be out of scope of this post.
Here is the method that I wrote to accomplish all of these DE update operations with different DE update modes (download the sample application for to find the method references used in the below code).
In the above method, we're actually getting the Job row effective as of the passed effective date(this will make that effective-dated row as current row) and then performing date-effective update operations basing on that row.
Instructions to run the sample application:
1. Create the required tables for illustrating date-effective operations executing the sql script downloading from here.
2. Unzip the sample application and, run the DemoAM. Input JobId, effective date and other attributes you want to update and click 'Execute'.
3. Change the date-effective update mode in method 'updateJobRow' each time you want to change the update mode(right now it's hard coded to EFFDT_UPDATE_CHANGE_INSERT_MODE), rebuild and continue. You can find the screen shots above how to provide input in AM Tester.
4. Query the DB to find the updated rows.
Enjoy!!!
Read more: Oracle ADF - Tips and Techniques: ADF Model: Different Date Effective Update Modes and behavior with Examples http://www.adftips.com/2011/01/adf-model-different-date-effective.html#ixzz0tONlNb3v

































